

文|半导体产业纵横
人类社会已经进入算力时代。
据中国信息通信研究院测算,截至2021年底,中国算力核心产业规模超过1.5万亿元,关联产业规模超过8万亿元。其中,云计算市场规模超过3000亿元,互联网数据中心(服务器)市场规模超过1500亿元,AI 核心产业规模超过4000亿元。
国内算力产业近五年平均增速超过30%,算力规模超过150EFlops(每秒15000京次浮点运算次数),排名全球第二,第一是美国。众多场景已经进入超越1000TOPS(Tera Operations Per Second, 处理器每秒可以进行一万亿次操作(1012))算力的时代。
超越1000 TOPS的高算力数据中心和超算
一个典型的超越1000TOPS算力的场景就是数据中心和超算。先来看数据中心对于算力的需求,工信部发布的《新型数据中心发展三年行动计划(2021-2023年)》明确了算力内涵并引入测算指标FLOPS,对数据中心发展质量进行评价,指出到2023年底,总算力规模将超过200 EFLOPS,高性能算力占比将达到10%,到2025年,总算力规模将超过300 EFLOPS。
而超算中心也早已迈入E级算力(百亿亿次运算每秒)时代,并正在向Z(千E)级算力发展。E(Exascale)级计算也就是百万兆级的计算,是目前全球顶尖超算系统新的追逐目标。用一个不精确的说法来解释百万兆级计算,一个百万兆级计算机一瞬间进行的计算,相当于地球上所有人每天每秒都不停地计算四年。
2022年5月登顶世界超算500强榜单的美国国防部橡树岭国家实验室Frontier超算中心,采用AMD公司MI250X高算力芯片(可提供383 TOPS算力),达到了1.1 EOPS双精度浮点算力。
人工智能
不断发展的人工智能也对芯片的算力提出更高的要求。人工智能的应用对于算力最大的挑战依然来自于核心数据中心的模型训练,近年来,算法模型的复杂度呈现指数级增长趋势,正在不断逼近算力的上限。
以2020年发布的GPT3预训练语言模型为例,其拥有1750亿个参数,使用1000亿个词汇的语料库训练,采用1000块当时最先进的英伟达A100 GPU(图形处理器,624 TOPS)训练仍需要1个月。
距离GPT-3问世不到一年,更大更复杂的语言模型,即超过一万亿参数的语言模型Switch Transformer已问世。目前,人工智能所需算力每两个月即翻一倍,承载AI的新型算力基础设施的供给水平,将直接影响AI创新迭代及产业AI应用落地。
AI模型跑步进入万亿级时代,深度学习发展逐步进入大模型、大数据阶段,模型参数和数据量呈爆发式增长,引发的算力需求平均每2年超过算力实际增长速度的375倍。
自动驾驶
自动驾驶任务需要高于1000 TOPS的高算力芯片。
自动驾驶的竞争实际上是算力的竞争。汽车从L1、L2向L3、L4、L5不断推进,从某种意义上看,就是算力的竞赛,每往上进阶一级就意味着对算力的需求更高。高阶自动驾驶对算力需求呈指数级上升。
2014—2016年特斯拉ModelS的算力为0.256TOPS,2017年蔚来ES8的算力是2.5TOPS,2019年特斯拉Model3算力为144TOPS,2021年智己L71070TOPS,2022年蔚来ET7是1016 TOPS。
综合考虑集成电路技术发展下的芯片算力现状和未来人工智能、数据中心、自动驾驶等领域的发展趋势,未来高算力芯片需要不低于1000 TOPS的算力水平。
市场对于算力需求的增长远远超过摩尔定律的演进速度。OpenAI的模型显示,2010年以来业内最复杂的AI模型算力需求涨了100亿倍。目前解决算力的方式80%依靠并行计算和增加投资,10%依靠AI算法进步,10%依靠芯片单位算力进步。
1000TOPS背后的“大算力芯片”单个芯片对于算力的追求是永无止尽的。目前来看,业内人士认为“单芯片算力达到100TOPS”就能称之为“大算力芯片”。
目前能够推出单芯片超越100TOPS的企业并不多,包括:AMD公司MI250X高算力芯片(可提供383 TOPS算力)、Mobileye EyeQ Ultra单颗芯片(算力可达176TOPS)等。
国内方面,寒武纪2021年也接连发布2款云端AI芯片,分别是思元290和思元370。思元370是寒武纪首款采用chiplet(芯粒)技术的AI芯片,集成了390亿个晶体管,最大算力高达256TOPS(INT8),是寒武纪第二代产品思元270算力的2倍。
此外,燧原科技、地平线、瀚博半导体、芯驰科技、黑芝麻智能等在2021年也都推出了大算力AI芯片,其中,燧原科技发布的“邃思2.0”,整数精度INT8算力高达320TOPS。
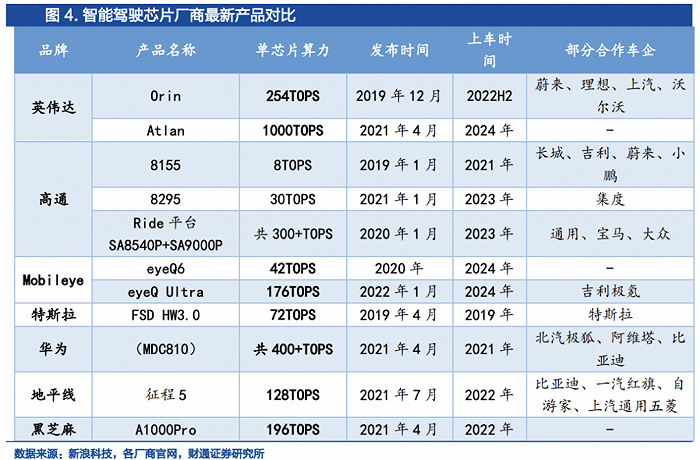
目前推出算力超越1000TOPS的SoC,唯有英伟达、高通,并且两家企业推出的高算力芯片主要用于自动驾驶领域。
首先来看英伟达,在2021年4月,英伟达就已经发布了算力为1000TOPS的DRIVE Atlan芯片。到了今年,英伟达直接推出芯片Thor,算力是Atlan的两倍,达到2000TOPS,并且在2025年投产,直接跳过了1000TOPS的DRIVE Atlan芯片。
其次是高通,今年同样推出集成式汽车超算SoC———Snapdragon Ride Flex,包括Mid、High、Premium三个级别。最高级的Ride Flex Premium SoC再加上AI加速器,其综合AI算力能够达到2000TOPS。
超强算力的背后,是利用SoC的片上整合。异构计算通过多种计算单元混合协作模式提升计算并行度和效率,在移动互联网、人工智能、云计算等各类典型应用中占比显著提高,并主要通过芯片内异构、节点内异构两种模式实现性能、功耗与成本间的最佳均衡。芯片内异构典型代表为 SoC 芯片,以英伟达的Thor为例,Thor之所以能实现如此高算力,主要得益于其整体架构中的Hopper GPU、Next-Gen GPU Ada Lovelace和Grace CPU。
高算力芯片如何进化实际上,芯片的算力由数据互连、单位晶体管提供的算力(通常由架构决定)、晶体管密度和芯片面积共同决定。因此想要实现算力的提高,需要从这几个方面入手。
算力进化的路径一:芯片系统架构的挑战
200TOPS以上的芯片对于访存能力的要求非常高,需要支持更高的带宽,这带来系统架构设计复杂度的大幅度提升。
当前芯片主要采用冯·诺依曼架构,存储和计算物理上是分离的。有数据显示,过去二十年,处理器性能以每年大约55%的速度提升,内存性能的提升速度每年只有10%左右。结果长期下来,不均衡的发展速度造成了当前的存储速度严重滞后于处理器的计算速度,出现了“存储墙”问题,最终导致芯片性能难以跟上需求。
英伟达提出的“黄氏定律”,预测GPU将推动AI性能实现逐年翻倍,采用新技术协调并控制通过设备的信息流,最大限度减少数据传输,来避免“存储墙”问题。
英伟达在GPGPU上迭代形成集成了张量核心(Tensor Core)的领域定制架构,2022年最新发布的H100 GPU基于4 nm工艺,可以提供2000 TFLOPS(万亿次浮点运算每秒)的算力。
算力进化的路径二:先进工艺平台的挑战
集成电路尺寸的微缩能够带来单位面积算力指数的提升。在相同架构的不同工艺下,随着工艺节点的缩小,英伟达GPU单位面积芯片算力持续提升。近年来,英伟达、AMD、苹果的高算力芯片均采用7、5 nm先进制程实现。本质上,算力提升的核心是晶体管数量的增加。
作为 Intel 的创始人之一,Gordon Moore 在最初的模型中就指明,无论是从技术的角度还是成本的角度来看,单一芯片上的晶体管数量不能无限增加;因此,业内在致力于提升晶体管密度的同时,也在尝试其他软硬件方式来提高芯片运行效率,如:异构计算、分布式运算等等。
算力进化的路径三:大尺寸芯片工程的挑战
大算力芯片的尺寸非常大,其在封装、电源和热管理、成本控制、良率等方面都存在严峻的挑战。芯片的价格当然是面积越大越贵,芯片面积扩大一倍,价格高3到5倍甚至更高。
根据近40年来芯片面积的变化趋势,可以看出随着高算力芯片的不断发展,面积也持续增大,当前已接近单片集成的面积极限。既然单颗芯片的面积不能无限增加,将一颗芯片拆解为多颗芯片,分开制造再封装到一起是一个很自然的想法。
异构集成+高速互联塑造了 Chiplet 这一芯片届的里程碑。如果使用芯粒(Chiplet)设计技术,通过把不同功能芯片模块化,利用新的设计、互连、封装等技术,在一颗芯片产品中使用来自不同技术、不同制程甚至不同工厂的芯片,解决了芯片制造层面的效率问题。
结语宏观总算力 = 性能 x 数量(规模) x 利用率。
算力是由性能、规模、利用率三部分共同组成的,相辅相成,缺一不可:有的算力芯片,可能可以做到性能狂飙,但较少考虑芯片的通用性易用性,然后芯片销量不高落地规模小,那就无法做到宏观算力的真正提升。
有的算力提升方案,重在规模投入,摊大饼有一定作用,但不是解决未来算力需求数量级提升的根本。
现阶段大国博弈加剧全球产业链、供应链重构,同时中国集成电路先进工艺的开发受到制约,单纯依靠先进制程等技术的单点突破成本高、周期长。
采用成熟制程和先进集成,结合CGRA和存算一体等国内领先的新型架构,在芯粒技术基础上实现晶圆级的高算力芯片是一条可行的突破路径,该路径能够利用现有优势技术,在更低的成本投入下,更快地提升芯片算力。
-PG电子(中国)官方网站