

文|经纬创投
5月29日,因为业绩远超预期,英伟达市值在一天之内暴涨了1800亿美元左右(1.3万亿人民币),这是美国历史上第二大单日最高市值涨幅,英特尔(Intel)的市值如今只有其九分之一。
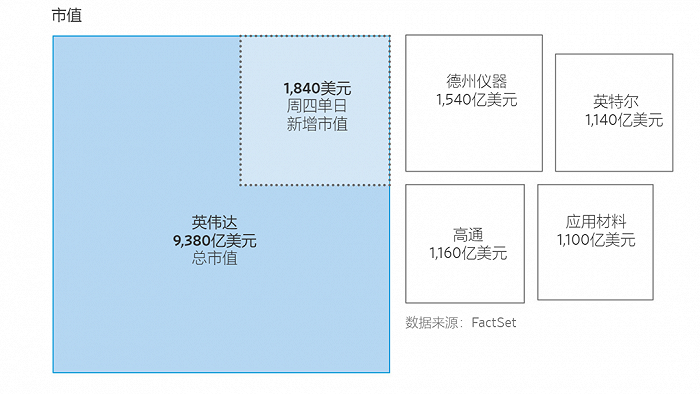
因为业绩远超预期,英伟达实现了美国历史上第二大单日最高市值涨幅。图片来源:WSJ
这次暴涨的推动力,是席卷全球的AI浪潮。英伟达首席执行官黄仁勋说,人工智能应用正推动对算力的需求,而英伟达的芯片是创造人工智能工具的关键。比如OpenAI构建ChatGPT背后,可能要用到1万枚左右英伟达GPU。
随着叱咤多年的摩尔定律逼近极限,我们开始需要其他技术来进一步提升算力。此时,“把电换成光”,成为了一个非常重要的选项。
光芯片很早就有,已经很成熟,但绝大多数是不可编程的光学线性计算单元。要想通过光来提升算力,具有实用价值的计算单元就必须具备可编程性,这种光芯片是最近10年才逐渐取得突破性进展的,本文所指的“光芯片”都是这种可编程的光计算芯片。
英伟达的暴涨代表了AI时代对算力的绝对重视,光芯片作为重要的潜在颠覆性技术路径,同样值得重视。光芯片商业化的两大思路,我们提前列在这里,本文最后一部分会详细分析:第一大思路是短期内不寻求完全替代电,不改动基础架构,最大化地强调通用性,形成光电混合的新型算力网络;第二大思路是把光芯片模块化,不仅仅追求在计算领域的应用,还追求在片上、片间的传输领域应用,追求光模块的“即插即用”。
今天这篇文章主要会涉及以下几点,当然需要多说一句的是,本文所主要介绍的思路,只是光计算芯片领域的其中一条重要路径,其他方案也在同步发展,同样值得关注,Enjoy:
▌摩尔定律逼近极限,未来如何提升算力?
▌一篇论文打开了光计算的大门
▌一个典型的光子计算矩阵是如何运作的?
▌光芯片的优势与挑战
▌光芯片如何商业化?
1、摩尔定律逼近极限,未来如何提升算力?在过去二十年中,算力发生了翻天覆地的变化。
如果你拿2010年的电脑和现在的相比,可能你会发现2010年的电脑还可以继续跑现在的一些软件。但如果你用2000年的电脑,去跑2010年的软件,你会发现99%的软件都跑不起来。
这说明了,电子芯片和算力的发展,其实是在逐渐变慢,背后的原因受制于物理极限,每一次芯片迭代所带来的算力红利,已经逐步减少,从16纳米到7纳米、再到5纳米,再往下一步的增长只会越来越小。
这主要受限于功耗和晶体管本身的密度。人们发现晶体管的尺寸越来越小,但并没有太好的办法让晶体管的能耗进一步下降。另外还受到铜导线的制约,因为随着铜导线的横截面积越来越小,电阻就会越来越高,于是发热也不是一直能往下降的因素。
另一个登纳德缩放比例定律——晶体管在密度提升的同时,功耗密度保持不变,这一定律早在2004年左右已经失效。随着芯片集成度的提升,所需的功耗和散热要求越来越大,产生了“功耗墙”问题。
如今从2016年、2018年到2020年,最先进的制程从16nm到7nm到5nm,性能提升实际上越来越慢,已经无法实现摩尔定律每18个月翻倍的速度。并且从研发难度和成本的角度,未来可能全球只有极少数几家足以继续往5nm以下发展。
从对算力的需求来看,随着AI的爆发,在未来 10 年里,用增长越来越缓慢的电子芯片,去匹配增长越来越快的数据需求,这可能是目前最大的挑战。
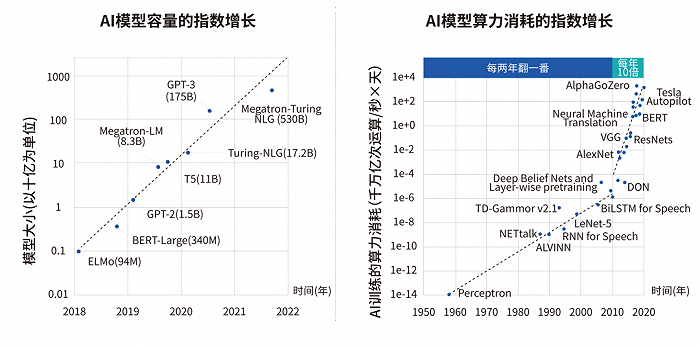
AI模型容量和算力消耗的指数增长趋势;来源:曦智科技《大规模光电集成赋能智能算力网络白皮书》,Wilfred Gomes et al., "Ponte Vecchio: A Multi-Tile 3D Stacked Processor for Exascale Computing," ISSCC, 2022
曦智科技创始人兼 CEO 沈亦晨经常把芯片设计比喻成城市发展,现在的芯片面积越做越大,比如2015年英伟达的GPU芯片,整个芯片从面积上来看大概有600平方毫米,但2020年推出的深度神经网络训练和推理芯片A100,它的面积大约是800多平方毫米。
拿城市发展作比喻,如果在500年前,想把100万人口的城市变成1000万,是非常困难的,因为受限于几个基础设施方面的问题:一是城市交通,如果用传统马车或步行,哪怕全都是平面道路,也很难满足交通需求。二是每栋楼房的设计,如果每栋楼房还是500年前的一层楼、两层楼,要想支撑起更大的城市体系也非常困难,只有出现了高层楼房,城市才能提高密度。
这个比喻对应了芯片设计中的片间网络和片上网络,如果把现在的电换成光,能在最基础的“基建技术”方面,帮助电子芯片进行下一代技术升级,“光替代电”能有效解决高通量和交通问题。
2、一篇论文打开了光计算的大门广义的光芯片,并不算是前沿技术,它存在的时间甚至比电子芯片还要久。
2000年前后的海底光缆,光通讯两端的收发模块都是光子芯片,甚至老师在上课时用的激光笔,里面也有激光器芯片,也是一种光子芯片。
但这些光芯片都是不可编程的,所以无法运用于计算领域。在计算方面,电子芯片独步天下。
直到2017年,沈亦晨等人在《自然·光子》(Nature Photonics)期刊上所发表的封面论文,开创性地提出了一种以光学神经网络为蓝本的全新计算架构,光子计算成为可能。

图片来源:Deep learning with coherent nanophotonic circuits,nature photonics
光学信号和光学器件与电子芯片遵循不同的物理原理。光计算理论比较复杂,简单解释是:光学信号与散射介质的互动在大多数情况下是线性的,因此可以被映射为一种线性计算。
生活中其实有很多光学线性计算的现象,一个典型的例子是光学照相机的镜头,镜头前的光学信号在穿过镜头时,完成了两次二维空间光学傅立叶变换,然后在感光元件上成像,因此,照相机镜头可以被看作一种不可编程的光学线性计算单元。
但要可编程,才有实用价值。在2017年的这篇论文里,沈亦晨等研究者提出的最重要的思路,就是用一个网络状的干涉器,在光通过干涉器的时候,利用它们相互之间的干涉和对干涉器的控制来进行线性运算,可以总结为用一个干涉器的集联来完成大规模的线性计算,以此应用于人工智能的矩阵计算。
当然这个是最初提出的理论,后来这个系统要想实际落地,远远比一个矩阵计算器要复杂得多。并且光还可以运用在很多方面,例如片上和片间的数据传输等等,之后的技术方案经历了多次迭代,变得越来越成熟。
在光计算芯片(硅光)上,一颗芯片需要集成上万个光器件,包括调制器、探测器、干涉器、波导、激光光源、混波器等等10种左右,这些都是纳米级。
光芯片的核心是用波导来代替电芯片的铜导线,来做芯片和板卡上的信号传输,其实就是换了一种介质。当光在波导里面传输的时候,波导和波导之间出现光信号干涉,用这个物理过程来模拟线性计算这一类的计算过程。
就像是光在凸透镜镜片里的传播过程,其实是模拟了一个类似傅里叶变换的数学过程。在光芯片里也是一样,光在芯片上波导传播的时候,当两个波导靠得很近的时候,里面的光信号就会相互干涉,这个干涉的过程就刚好模拟了一个线性计算过程。当有很多个波导,比如128根波导形成一个网络互相干涉的时候,我们就可以通过控制这些波导的干涉,来模拟任何一个通用的矩阵运算。

可编程光学系统的研究突破。图片来源:Deep learning with coherent nanophotonic circuits,nature photonics
3、一个典型的光子计算矩阵是如何运作的?举一个实际的例子,一个典型的光子矩阵计算是如何运作的?
首先最左边是数据加载,中间是矩阵,最右边是光信号接收,这个过程可总结为光信号通过矩阵接收的过程。
如果拿现实生活中的现象作类比,就类似于眼镜,近视的朋友在没有戴眼镜之前,眼前的世界是不清晰的,但戴了之后就变清晰了,而这个从模糊到清晰的过程,就是眼镜对图像信号做了一种处理,也可以理解成一种计算。这个计算的实现方法是眼镜前的光信号,通过眼镜这个计算单元来完成。
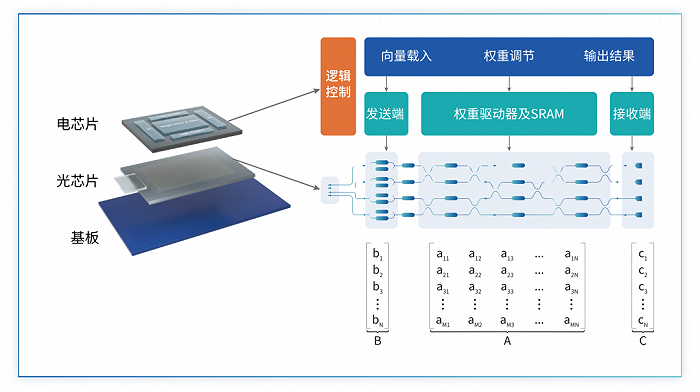
可编程光子矩阵乘法器原理示意图,在这个例子中,所有的光器件都集成在一块光芯片上,而光芯片的控制电路和内存都部署在电芯片上。图片来源:曦智科技《大规模光电集成赋能智能算力网络白皮书》
在2020年的一份视频演示中,曦智团队在原型产品上成功用光子芯片运行了Google Tensorflow自带的卷积神经网络模型,来处理MNIST数据集,这是一个使用计算机视觉识别手写数字的基准机器学习模型,也是机器学习中最著名的基准数据集之一。在测试中,整个模型超过95%的运算是在光子芯片上完成的处理。
测试结果显示,光子芯片处理的准确率已经接近电子芯片(97%以上),另外光子芯片完成矩阵乘法所用的时间是当时最先进的电子芯片的 1/100 以内。这也是世界上第一台完全独立的光学计算系统。

曦智科技开发的早期产品。图片来源:曦智科技
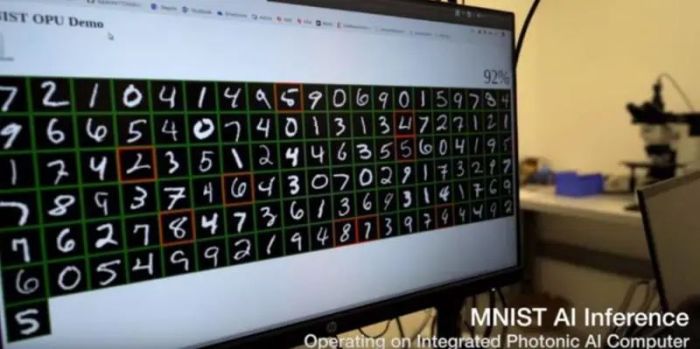
这款初代产品正在处理MNIST数据集。图片来源:曦智科技
4、光芯片的优势与挑战光芯片的优势可以总结为:速度快/低延迟、低能耗、擅长AI矩阵计算。
首先是速度快/低延迟。光信号意味着光速,所以光计算芯片最显著的优势是速度快、延迟低,在芯片尺寸的厘米尺度上,这个延迟时间是纳秒级(小于5纳秒),这个速度是非常惊人的。并且这个延迟与矩阵的尺寸几乎无关,在尺寸较大的情况下,光子矩阵计算的延迟优势非常明显。
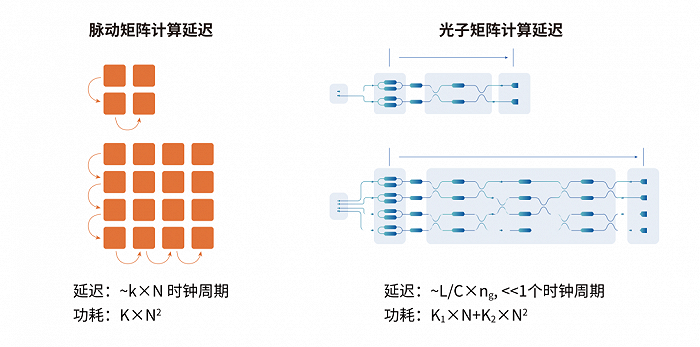
脉动矩阵计算和光子矩阵计算延迟对比示意图。图片来源:曦智科技《大规模光电集成赋能智能算力网络白皮书》
第二大优势是低能耗。镜片折射本身是不需要能量的,是一个被动过程,不耗能。当然,在实际应用中,由于要对计算系统编程,其中光信号的产生和接收还是需要耗能的。在光学器件和其控制电路被较好地优化前提下,基于相对传统制程的光子计算的能效比,可媲美甚至凌驾先进制程的数字芯片。
第三大优势是擅长矩阵运算。光波的频率、波长、偏振态和相位等信息,可以代表不同数据,且光路在交叉传输时互不干扰,比如两束手电筒的光束交叉时,会穿过对方光束形成“X”型,并不会互相干扰。这些特性使光子更擅长做矩阵计算,而AI大模型90%的计算任务都是矩阵计算。
以上我们谈到了很多优势,但光芯片作为一项前沿技术,必然有很多挑战有待克服,下面我们就聊几个有待克服的难题。
首先由于要用于复杂计算,那么光器件的数量必然就会很多,要达到不错的性能至少需要上万个,这也会带来更复杂的结构和更大的尺寸。为了实现可编程,必然要对每个器件进行控制,也会要求高集成度。
这些要求会产生一些工艺上的挑战,同时导致成本很高,以及整体稳定性、生产良率都有挑战,所以必须找到一种低成本、高良率的方法,来控制大量光器件的技术。曦智采取的是3D堆叠的封装技术,在光芯片上方堆叠电芯片,电芯片可以集成各种各样的功能。电芯片、光芯片通过凸块上的调制器进行信号转换,把数字信号变成模拟信号去控制光器件,然后再返回。这时才能达到对复杂芯片的有效控制,最终作为一个整体集成在基板上,成为一个产品。
同时温度也是需要一定的控制,因为环境温度会对计算精度产生影响。因为是模拟计算,当整个环境对电芯片产生影响的时候,对光信号也会产生扰动。有一种办法是把整个芯片放在恒温环境下,通过温控电路来实现。但这会牺牲一些光计算的低能耗优势,因为如果为了控制它的精度而消耗很多能量,会有些得不偿失。
对于温度控制,还包括芯片内部发热,导致对周边器件的影响问题。比如两个器件靠很近,一个器件在发热,旁边会受影响。
另一个挑战是应用层面的精度问题。因为光计算是模拟计算,精度受限于物理本质,同水平下精度较难与数字计算一样。当然如果要想达到高精度(12比特、16比特等),也可以实现,但代价会非常大,所以核心是要寻求合适的应用场景,实际上在人工智能算法方面,并不需要那么高的精度。
以上这些都是可以预料到的技术挑战。
5、光芯片如何商业化?光芯片看起来是很不错的技术路径,但到底多久才能落地?
我们总结了当下市场中,其中一种比较快的商业化路径思路:
第一是短期内不寻求完全替代电,不改动基础架构,最大化地强调通用性,形成光电混合的新型算力范式。
第二是把光芯片模块化,不仅仅追求在计算领域的应用,还追求在片间传输光模块的“即插即用”。
硅光芯片不是靠尖端制程来获胜,更多是靠速度和功耗,比如光的调制解调的速度、功耗,还有多波复用,在一个波导里面同时能通过多少路光等等。所以光芯片的“摩尔定律”不体现在制程,而是主频和波长。
通过上文所说的商业化路径两点思路,可以看出硅光最大的优势在于技术通用性。例如在一个GPU中,有专门做线性计算的计算核部分,它可能占到整个芯片四分之一到三分之一的大小,可以优先把这部分换成光的计算核。
同时,尽量不调整其他部分,最终对于软件开发者或是使用芯片的人来说,甚至不会注意到这个改动。如果拿从燃油车迭代到电动车的过程来做比喻,司机不用改变驾驶习惯,油门、刹车的位置都不变,背后是发动机换成了电机。
无论是生产商还是客户,最大的诉求之一就是要确保通用性。越大的客户越想要这个产品实现“开箱即用”,才能够最大限度降低学习成本,不需要对现在的底层框架进行过多修改,就能够适配到成千上万个当前的应用场景中。所以不动基础架构,而是把线性计算的计算核部分用光来部分替代,形成光电混合的算力网络新形式,是最快的商业化路径。
从算力提升角度来看,一个计算系统主要有三块计算要素:数据处理、数据传输、数据存储。以上所说的是针对第一部分数据处理,可以用光代替电芯片来做大部分矩阵运算类的数据处理。
第二部分是数据传输,包括一块芯片上的数据传输,和芯片之间的数据传输,也就是片上互连和片间互连,这两部分也是光子芯片的用武之地。
我们简单介绍一下片上光网络和片间光网络:
用片上光网络(Optical Network On Chip,oNOC)来代替模块间的电互连,可以利用光的低延迟和低能耗优势。如下图所示,两个电芯片被堆叠在同一个光芯片上,电芯片之间的数据传输由光芯片上的光波导链路实现。由于光传输很快,所以无所谓距离有多远,片上光网络可以覆盖大量的长距离通道。光芯片能够扩展到整个晶圆,从而实现晶圆级的光互连网络。在这样的状态下,把计算任务映射到不同芯片的工作可以达到更高的利用率。
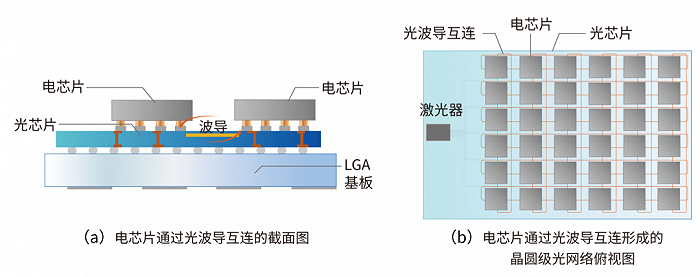
片上光网络系统侧视图与俯视图。来源:曦智科技《大规模光电集成赋能智能算力网络白皮书》
而对于片间光网络,目前在电芯片中,是通过以太网卡来实现互连,但它受限于互连延迟和带宽,在整体效率上有较大提升空间。利用光的优势,一种优化办法是取消网卡,将计算芯片直接和光电转换模块连接,以实现低延迟、高带宽、低能耗的片间光网络,当然这里面需要物理层和互连协议两方面的创新。
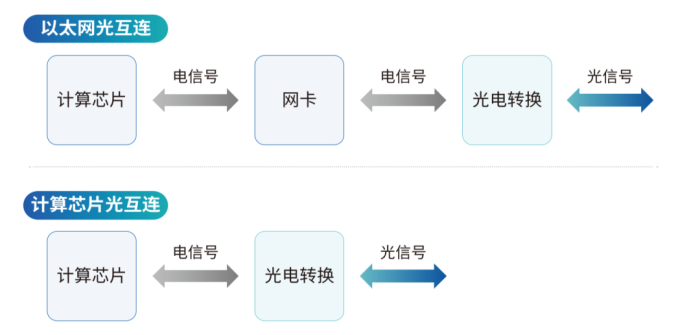
片间光网络示意图。来源:曦智科技《大规模光电集成赋能智能算力网络白皮书》
综合来说,结合光子矩阵计算(oMAC)、片上光网络(oNOC)和片间光网络(oNET)等新技术,可以构建光电混合数据中心。
片上光网络(晶圆级)可以令光计算芯片和传统电芯片有效协同,在单节点提高算力;片间光网络支持了高效传输和算力池化,使得大型分布式计算系统可以实现前所未有的高效、灵活和节能。
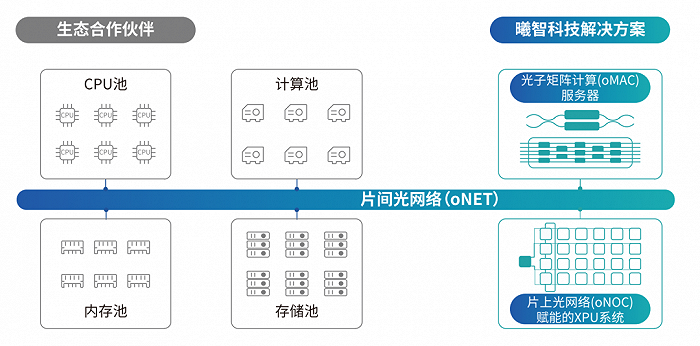
光电集成技术的光电混合数据中心示意图。来源:曦智科技《大规模光电集成赋能智能算力网络白皮书》
从商业化角度,除了做整个光计算完整的解决方案以外,还可以把某些单个技术模块化,比如刚刚所说的光计算(矩阵运算),或是光片上互连、片间互连,这些技术也可以模块化成为产品。如果拿智能电动车行业作类比,就像除了做整车以外,电池、电机、操控系统等等都是单独的模块化产品,很多电芯片的设计公司也确实有相关需求。
总之,光子计算提供了一条超越摩尔定律的算力提升路径。
光子计算这个方向在过去五年中逐渐变热,除了像英伟达这样的芯片设计巨头有布局,最近2-3年国际上一些晶圆厂、EDA公司、封测厂等等,也开始正式布局硅光产线。硅光芯片虽然当下还主要是在光通讯、光传感的激光雷达等领域,这部分需求也驱动了相关的供应链投入。虽然光计算还没有完全落地,但硅光芯片每个产业链环节的全面性,是光计算芯片量产的前提。并且晶圆厂也无需为光芯片重新开发一整套工艺,很多工艺都是通用的。
展望未来,光计算芯片最大的应用场景,就是人工智能。其他的还包括自动驾驶、金融(追求低延迟的量化基金)等领域,以及未来很多科研包括对大气、地理、新材料和药物研发,都可以通过算力更高的光电混合芯片来提高现有研发进度。
对于这种前沿技术,我们要观察什么指标来判断它的发展进度?其中一个核心指标是集成度,就是光电混合芯片能集成多少光器件,并且能精确控制它们。
这是一个全新的赛道,“超越摩尔定律”也是一个激动人心的口号,但几乎没有前路可以借鉴,开拓者们正在披荆斩棘,技术挑战与商业化风险并存。但唯一可以确定的是,人类社会对提升算力的追求,正比以往任何一个时刻更加迫切。
References:
1、 曦智科技,《大规模光电集成赋能智能算力网络白皮书》
2、 曦智科技CTO孟怀宇,《集成光子学在计算领域的机会与挑战》
3、 曦智科技创始人兼CEO沈亦晨等,《Deep learning with coherent nanophotonic circuits》(自然·光子杂志)
4、 量子位,比RTX3080快350倍,光子芯片真的能帮我们实现“换道超车”吗?
5、 DeepTech,曦智科技发布全球首个光子AI芯片原型
6、 智东西:掀起数据中心算力新风口!大规模光电集成有多硬核?
-PG电子(中国)官方网站