

文|融中财经 郑伟
编辑|吾人
全球范围内,“百模大战”不断升级,高端AI算力卡成为“硬通货”。以英伟达为例,依据当前订单情况和生产进度,现阶段的A800/H800交货时间都已经排到了今年年底与明年年初。英伟达(Nvidia)彻底“赢麻了”,也一度掀起资本追逐人工智能芯片的热潮。
近日,位于硅谷的人工智能芯片初创公司D-Matrix就成功收获1.1亿美元(约合8.02亿元人民币)的B轮融资。此次融资领投方是新加坡头部投资集团淡马锡(Temasek),微软、三星等知名科技巨头以及加州Playround Global等众多风险投资公司则纷纷跟投。此前,D-Matrix亦曾受到来自Marvell、海力士、爱立信等知名科技企业的投资。
01 进击中的D-Matrix成立于2019年的D-Matrix,是一家为满足数据中心高性能计算和人工智能算力而组建的芯片初创企业,此前一直专注于定制AI芯片的研发。其使命是凭借创新性的“数字存算一体(DIMC)”架构,来解决计算-存储集成问题,从而提高人工智能算力的效率。
D-Matrix由两位经验丰富的AI硬件专家Sid Sheth(创始人兼首席执行官)和Sudeep Bhoja(创始人兼首席技术官)领导。两位创始人在半导体领域有着超过20年的从业经历,曾在半导体巨头博通担任过总监职位,并在国际半导体公司Inphi(现已被Marvell收购)担任过高管职位。

业绩方面,D-Matrix已经出货了超过1亿颗芯片,收益突破了10亿美元(约合72.92亿元人民币)。根据著名数据分析公司Crunchbase的调查显示,D-Matrix现仅拥有11-50名员工。尽管员工数量相对较少,但自从OpenAI凭借ChatGPT成功击败Google之后,此类以少胜多的情况似乎变得更为常见了。
通过“数字存算一体”架构,D-Matrix的芯片能够确保高效的AI代码运行,简化数据处理流程,并实现对生成式AI(AIGC)需求的无缝响应。这些经过优化后的AI定制芯片,可以为OpenAI的ChatGPT等AIGC应用提供最佳的算力支持,这也是D-Matrix的市场潜力所在。
不过,为了在现阶段避免与英伟达的直接竞争,D-Matrix的技术瞄准了人工智能处理的“推理”部分,而不是AI大模型的训练部分。AI推理阶段,是指利用训练好的模型,通过输入新数据来推理出各种结论的过程。借助神经网络模型进行计算,利用输入的新数据来一次性获得正确结论的过程。这也过程也被称为预测或推断。
一般来说,根据承担任务的不同,AI芯片可被分为训练AI芯片和推理AI芯片。其中,训练芯片被用于构建神经网络模型,注重绝对的计算能力。在此领域,英伟达占据了强势的市场主导地位。据最新数据显示,在全球AI训练芯片市场,英伟达可占到80%到95%份额。而推理芯片,则是利用神经网络模型进行推理预测,产品往往更注重综合指标,如单位能耗算力、时延、成本等各方面表现都要考虑。D-Matrix主打的就是后者。
对于此次融资,D-Matrix创始人兼首席执行官Sid Sheth向媒体表示,D-Matrix计划将新资金投资于旗舰产品Corsair平台的商业化和人才招募。该平台是一款PCI外形的算力卡,采用DIMC架构和芯粒(Chiplet)技术,其创新性地支持将AI模型完全存储于内存中,可有效提高推理效率,并降低功耗和成本。
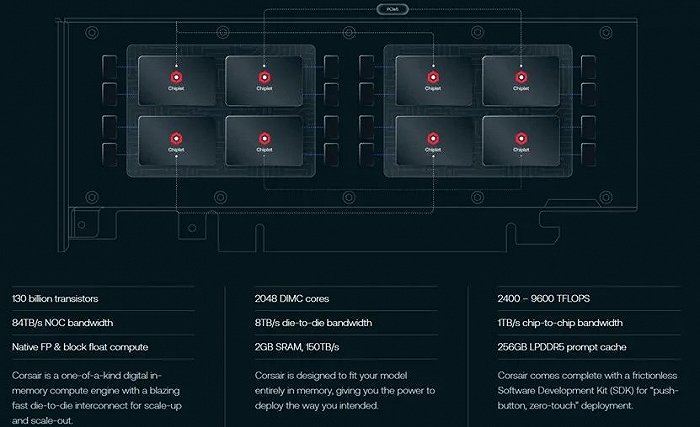
Corsair平台参数(图片来自于www.d-matrix.ai)
Corsair计划于2024年全面推出,其可以与机器学习工具链和相关服务器软件配合使用。这些软件主要由开源软件构建。用户只需简单操作,即可快速将AI模型导入到卡中,无需重新训练。
02 PK英伟达最强GPU,性能超9倍尽管GPU在游戏和“挖矿(生产加密货币)”方面表现出色,但对于AIGC来说,并非都是最佳选择。比如运行AI推理时,往往需要大量特定的内存带宽,而GPU的大部分时间处于空闲状态,只是等待更多数据从DRAM中传输出来。这就为AI推理设置了性能上限,不仅让吞吐量降低,延迟也会增加,同时还需要额外能量来提高功率和冷却成本。截至目前上述情况仍未有太大的变化,很多企业仍然依靠堆大量的GPU去做AI训练和推理,导致成本负担高企。
以OpenAI为例,就身陷有热度、没收入的囧地。有报告指出,ChatGPT每天要烧钱约70万美元(约合509.65万元人民币),而这个数字还不包括招募和支付顶尖人才的薪资费用。以这样的烧钱速度算,OpenAI甚至难以维持到明年年底。
OpenAI后续具体如何规划尚未可知,D-Matrix却早已为AI推理的降费增效谋划了新路径。D-Matrix的旗舰产品Corsair C8卡包括2048个DIMC内核、1300亿个晶体管和256GB LPDDR5 RAM。它拥有2400至9600 TFLOPS(每秒浮点运算次数)的计算性能,芯片间带宽为1TB/s。凭借在计算架构、电源能耗和低延迟软件堆栈方面的创新突破,D-Matrix的Corsair C8在实际测试中击败了Nvidia H100,吞吐量超越了9倍,而运行成本则降低了10倍至20倍,甚至在某些情况下可以降低60倍。
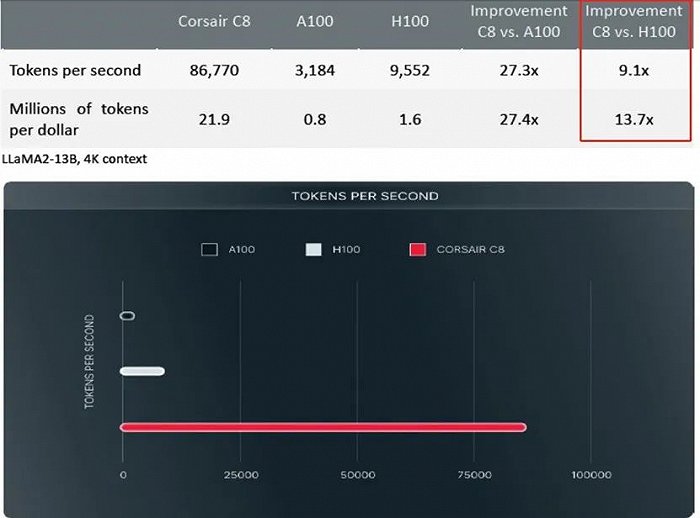
实测中Corsair C8吞吐量超越Nvidia H100的9倍(图片来自于www.d-matrix.ai)
举个例子,如果有人想使用LLaMA2生成与维基百科一样多的内容,她需要生成57亿个词元(Tokens)才能最终达到维基百科43亿个单词的量级。但是通过使用D-Matrix解决方案的单个推理节点,AI大模型可以在18小时内产出整个维基百科的数据量。
如果将 D-Matrix 技术与微软低代码强化学习平台 Project Bonsai 相结合,甚至还可以围绕 DIMC平台创建高效编译器。Project Bonsai提供了训练有素的RL代理的快速原型设计、测试和部署,以加速编译器堆栈的开发过程。同时,结合D-Matrix的低功耗AI推理技术,该技术可提供比旧架构高出10倍的能效,使得编译器的性能得到显著提升。
Sid Sheth表示:“目前由于推理成本较高,生成式人工智能在商业上的应用仍面临着挑战,但是通过新的资金注入,我们将能够比其他竞争对手更快地将商业上可行的解决方案推向市场。”
微软作为D-Matrix的投资方,表示将在明年采用D-Matrix的AI芯片到相关业务上,以缓解算力不足的问题。有机构预测,未来两年内,D-Matrix的年收入有望达到70~75万美元(约合509.65~546.05万元人民币)。
03 大鱼吃小鱼,小鱼未必找得到虾米今年,像D-Matrix这样幸运地拿到融资的美国芯片初创公司,实际上已是少数。随着英伟达在AI芯片市场上主导地位日益显现,相关领域的芯片初创企业的日子并不好过,融资时遭遇挑战更是家常便饭。数据统计,在2023年第二季度,芯片领域初创公司在美国的融资交易数量上较2022年同期暴降了80%。
对于芯片初创公司来说,将芯片从最初的设计阶段推进到商用阶段,可能至少需要超过5亿美元(约合36.41亿元人民币)的投资,而一旦出现投资者无法履约或者撤资,将快速切断这些初创公司的现金流,导致生存危机。对于投资者来说,此类芯片初创公司不仅投资回报周期长,风险还极高,所以在全球经济低迷的大环境下,往往更不愿大量投入资金。
根据风险资本调研公司PitchBook的数据显示,截至今年8月底,美国的芯片初创企业仅仅融资8.814亿美元,而在2022年的前三个季度为17.9亿美元。交易数量也从23宗降至4宗。
以AI芯片初创公司Mythic为例,此前共融资约1.6亿美元,但到2022年时,现金已消耗殆尽,公司运营面临停摆。所幸在今年3月份,该公司成功获得了新的投资,尽管只有1300万美元。
Mythic首席执行官Dave Rick表示,英伟达“间接”加剧了整个AI芯片行业的融资困境,因为投资者往往期待“投资那些回报丰厚的项目”。而英伟达的一家独大,叠加全球经济消极影响因素,让周期性的半导体行业雪上加霜。
有芯片从业人员指出,现阶段想融资愈发艰难,投资者会提出更为严苛的要求。比如公司需要至少拥有一种成熟产品,这个产品要么已经在市场上销售,要么有能力在几个月内发布。另外,在融资金额方面也大不如前。今年以来,对芯片初创公司的金额仅在1亿美元左右,而在2年前,对于芯片初创企业的新投资往往能够达到2亿或3亿美金。
而如D-Matrix这样的创业公司似乎也不敢同英伟达正面硬刚,选择了AI推理芯片赛道一样。“只有少数公司真正有机会与英伟达竞争,”正如业内分析师Karl Freund表示。“D-Matrix 就是其中之一。他们使用不同的技术、不同的架构,似乎可以产生更好的结果。”
04 存算一体受青睐,国内玩家知多少实际上,D-Matrix备受关注的原因,一方面是面向AI推理的性能优势,另一方面采用了更加适合AI计算的存算一体理念。而“存算一体”并不是近几年才被提出的新概念。早在上个世纪70年代,存算一体就已经被提出,只是受限于当时的芯片制造技术和算力需求,这一设想仅停留在理论研究阶段。直到进入大数据和人工智能时代,巨大的算力需求为存算一体架构的发展提供了新的舞台。
当前,市面上的传统芯片普遍都采用冯诺依曼架构。该架构的特点是将处理单元和存储单元分开,需要进行计算时,处理单元从存储单元中读取数据进行处理,处理完成后再将数据返回存储单元。然而,存算一体架构将存储单元和处理单元合二为一,将数据和计算融合在同一片区域内。这样做的好处是可以直接利用存储器进行数据处理,从根本上消除了冯诺依曼架构计算存储分离的问题。尤其在现代大数据和大规模并行的应用场景中,存算一体架构非常适用。
目前,国内外很多企业纷纷展开存算一体技术的研发,其中包括英特尔、IBM、华为、三星、阿里巴巴、SK海力士、美光、台积电等一众知名公司,几乎都在积极布局近存计算领域。据不完全统计,A股市场中涉及存算一体技术的公司,包括东芯股份、恒烁股份、罗普特、首都在线、长电科技、澜起科技和润欣科技等。同时,国内初创公司如千芯科技、亿铸科技、知存科技、苹芯科技和后摩智能等均获资本市场青睐,其中多家更是连续两年获得融资支持。
以千芯科技为例,就已拥有面向数据中心的大算力计算板卡和计算IP核,以及多并发实例核心技术(该技术NVIDIA在2019年集成入GPU)。其可支持ARM核心Stacking,具备轻量GPU技术,可基于SRAM/RRAM/MARM存储单元,可为客户提供灵活易用的AI推理计算加速及一站式解决方案。通过千芯科技自研存算一体技术,可提供能效比超过10-100TOPS/W,优于其他类型AI芯片 10-40倍的吞吐量支持。
尽管全球范围内无论学术界还是工业界都开始对存算一体展开资源投入,但在大模型火起来之前,存算一体的研究还是相对零散的技术攻关,缺乏面向大算力方向的整体布局,亦缺乏主导的应用需求驱动,因此距离大规模进入市场或许还需要一定的时间。
不过令人期待的是,大模型已然成为存算一体大算力芯片的核心应用场景,而它对算力能效和密度有强烈需求,这正是存算一体的优势所在。为了面向大模型的部署,芯片从业者更需要对存算一体进行体系化布局,包括算法、框架、编译器、工具链、指令集、架构、电路等各个层次方面的协同设计,以形成全栈式的体系、工具链和生态链。相信随着存算一体芯片技术的进一步落地应用,AI大模型必将获得新的性能飞跃,从而推动数智化时代的加速到来。
-PG电子(中国)官方网站